用sharding技术回扩展你的数据库 (二)
日期:2014-05-16 浏览次数:21107 次
本部分首先简单介绍sharding系统的基本架构,然后重点介绍sharding机制中常用的三种表数据划分方法。
?
一.? 数据划分算法
?
1. Sharding 系统的基本结构
?
上节我们说到Sharding可以简单定义为将大数据库分布到多个物理节点上的一个分区方案。每个shard都被放置在一个节点上面。 Sharding系统是一个shared-nothing的系统,基本上都采用下图中所示的架构。最下面是很多数据库服务器节点,每个节点上面都会运行一 个或多个数据库的实例。中间一层叫做查询路由器,客户端的连接都通过它进行转发。查询路由器负责解析用户的查询语句,并将这些语句转发到包含有所需要的数 据的shard节点上面去执行。执行的结果也会通过查询路由器进行汇总并发送给相应的客户端。
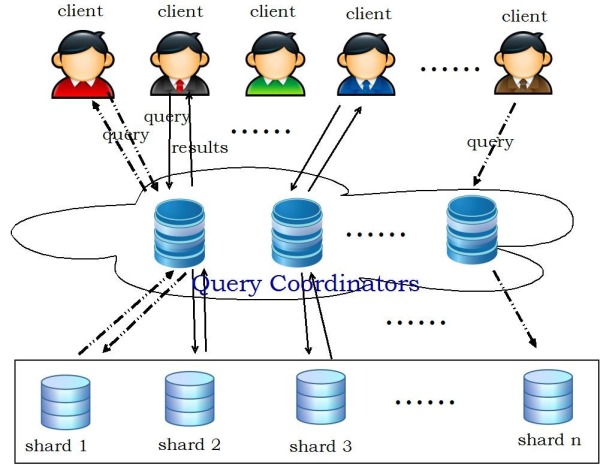
?
对于这样一个sharding系统,我们需要考虑到下面几个问题:如何将数据划分到多个shard节点上面;用户的查询语句如何正确的转发到相应的 节点上面去执行;当节点数据变化的时候怎样重新划分数据。对于数据划分和查询路由来说,所用的算法一般是对应的。下面就讲一下一些常用的数据划分的方法。 这里的假设前提是:只考虑单个表,并且这个表的划分键(Partitioning Key)已经被指定。
?
2. 常见的表划分算法
本节介绍三种常见的数据划分方法:轮流放置(Round-Robin)、一致性哈希(Consistent Hashing)和区间划分(Range-based Partitioning)。
?
2.1 Round-Robin
?
轮流放置是最简单的划分方法:即每条元组都会被依次放置在下一个节点上,以此进行循环。一般在实际应用中为了处理的方便,通常按照主键的值来决定次 序从而进行划分。即给定一个表T,表T的划分键 (Partitioning Key) 是k,需要划分的节点数目N,那么元组t ∈ T将会被放置在节点n上面,其中n = t.k mod N。由于划分只与划分键有关,因此我们可以把对元组的划分简化为对数字的划分,对于不是数字的键值可以通过其它方式比如哈希转化为数字形式。下面给出一个 例子来表示这种划分方式,把9个元组分布到3个节点上的情况。
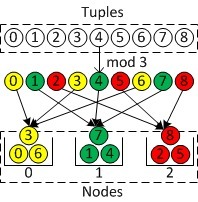
但是,简单的直接用划分键上的值来计算放置节点的算法可能会造成数据的不均匀。因此,轮流放置有很多改进版,比如说哈希 方式(Hashing),即n = hash(t.k) mod N。先将划分键的值进行hash操作,变成一个与输入分布无关、输出均匀的值,然后再进行取模操作。哈希函数可以有很多选择,你可以针对你的应用的特征去 选取。
?
Pros: 轮流放置算法的实现非常简单,而且几乎不需要元数据就可以进行查询的路由,因此有着比较广泛的应用。例如EMC的Greenplum的分布式数据仓库采用的就是轮流放置和哈希相结合的方式。
?
Cons: 轮流放置同样具有很明显的缺点:当系统中添加或者删除节点时,数据的迁移量非常巨大。举个有20个节点的例子(下表),当系统由4个节点变为5个节点时, 会有如下的放置结果:红色部分是mod 4和mod 5时结果不相等的情况,不相等意味着这些元组当系统由4个节点变为5个节点时需要进行迁移。也就是说多达80%的元组都需要迁移。数据的迁移会对系统的性 能造成很大的影响,严重时可能会中断系统的服务。当系统的节点数目频繁变化时,是不提倡使用这种方式的。
?

?
数据迁移量大的问题可以通过改进轮流放置算法来达到,比较常见的两个改进算法是一致性哈希和分区划分算法。
?
2.2 Consistent Hashing
?
一致性哈希是一种特殊的哈希方式。传统的哈希方式(在上一小节中讲到)在当节点数目发生变化时,会引起大量的数据迁移。 而使用一致性哈希则不会产生这种问题。一致性哈希最早是一个分布式缓存(Distributed Caching)系统的放置算法(现在很热门的Memcached就用的是一致性哈希)。但是现在它已经被广泛应用到了其它各个领域。对于任何一个哈希函 数,其输出值都有一个取值范围,我们可以将这个取值区间画成一个环,如下图所示:
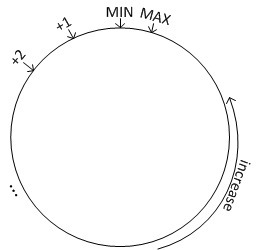
通过哈希函数,每个节点都会被分配到环上的一个位置,每个键值也会被映射到环上的一个位置。这个键值最终被放置在距离该 它的位置最近的,且位置编号大于等于该值的节点上面,即放置到顺时针的下一个节点上面。下图形象的表示了这种放置方案,其中Node 0上面放置Range 0上面的数据,以此类推。
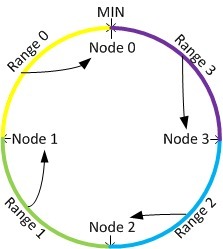
?
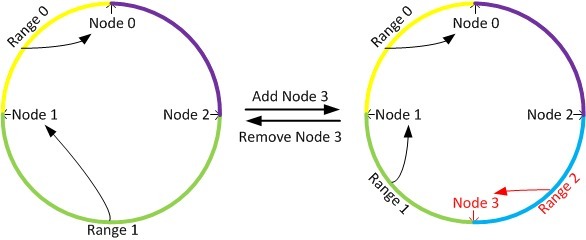
Pros: 由于采用的哈希函数通常是与输入无关的均匀函数,因此当键值和节点都非常的多的时候,一致性哈希可以达到很好的分布式均匀性。并且由于特殊的放置规则,一 致性哈希在节点数据发生变动时可以将影响控制在局部区间内,从而保证非常少的数据迁移(接近理论上的最小值)。当增加一个节点时,只有这个节点所在的区间 内的数据需要被重新划分,如下图中,只需要将range 2上面的数据会从node 1中迁移到node 3上面。当删除一个节点时,只需要将这个节点上面的数据迁移到下一个节点上面,比如删除node 3,只把range 2上面的数据迁移到node 1上面就可以并,而其它的数据是不需要迁移变动的。
?
?
一致性哈希有非常广泛的应用,Key-Value系统,文档数据库或者分布式关系数据库都可以使用。Amazon的 NoSQL系统Dynamo应用采用的就是一种改进的一致性哈希算法。在这个系统中又引入了虚拟节点的概念,使得这个算法的load balance更加的好,并且同时考虑了复制技术。环上的点就变成了虚拟节点,然后再采用其它的方式将这些虚拟节点映射到实际的物理节点上面去。这使得系 统有很好的可扩展性和可用性。
?
2.3 Range-Based Partitioning
?
区间划分是现在很热门的NoSQL数据库MongoDB的sharding方案中所使用的算法。系统会首先把所有的数据 划分为多个区间,然后再将这些区间分配到系统的各个节点上面。最简单的区间划分是一个节点只持有一个区间:在有n个节点的情况下,将划分键的取值区间均匀 划分(这里的均匀是指划分后的每个partition的数据量尽量一样大,而并非值域区间一样大)为n份,然后每个节点持
