Leveldb源码分析-12
日期:2014-05-16 浏览次数:20757 次
8 FilterPolicy&Bloom之1
8.1 FilterPolicy
FilterPolicy有3个接口:
virtual const char* Name() const = 0; // 返回filter的名字
virtual void CreateFilter(const Slice* keys, int n, std::string* dst)const = 0;
virtual bool KeyMayMatch(const Slice& key, const Slice& filter)const = 0;
> CreateFilter接口,它根据指定的参数创建过滤器,并将结果append到dst中,注意:不能修改dst的原始内容,只做append。
参数@keys[0,n-1]包含依据用户提供的comparator排序的key列表--可重复,并把根据这些key创建的filter追加到@*dst中。
> KeyMayMatch,参数@filter包含了调用CreateFilter函数append的数据,如果key在传递函数CreateFilter的key列表中,则必须返回true。
注意,它不需要精确,也就是即使key不在前面传递的key列表中,也可以返回true,但是如果key在列表中,就必须返回true。
涉及到的类如图8.1-1所示。
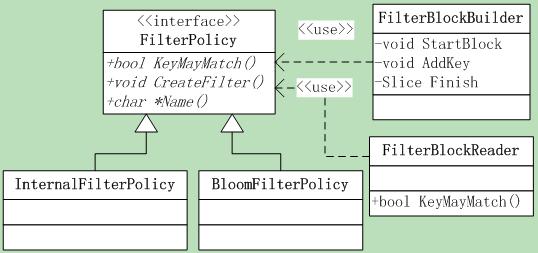
图8.1-1
8.2InternalFilterPolicy
这是一个简单的FilterPolicy的wrapper,以方便的把FilterPolicy应用在InternalKey上,InternalKey是Leveldb内部使用的key,这些前面都讲过。它所做的就是从InternalKey拆分得到user key,然后在user key上做FilterPolicy的操作。
它有一个成员:constFilterPolicy* const user_policy_;其Name()返回的是user_policy_->Name();
bool InternalFilterPolicy::KeyMayMatch(const Slice& key, constSlice& f) const {
returnuser_policy_->KeyMayMatch(ExtractUserKey(key), f);
}
void InternalFilterPolicy::CreateFilter(const Slice* keys, int n,std::string* dst) const {
Slice* mkey =const_cast<Slice*>(keys);
for (int i = 0; i < n; i++)mkey[i] = ExtractUserKey(keys[i]);
user_policy_->CreateFilter(keys, n, dst);
}8.3 BloomFilter
8.3.1 基本理论
Bloom Filter将元素映射到一个长度为m的bit向量上的一个bit,当这个bit是1时,就表示这个元素在集合内。使用hash的缺点就是元素很多时可能有冲突,为了减少误判,就使用k个hash函数计算出k个bit,只要有一个bit为0,就说明元素肯定不在集合内。下面的图8.3-1是一个示意图。
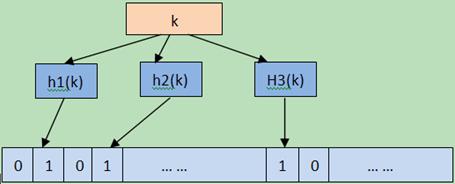
图8.3-1
在leveldb的实现中,Name()返回"leveldb.BuiltinBloomFilter",因此metaindex block 中的key就是”filter.leveldb.BuiltinBloomFilter”。Leveldb使用了double hashing来模拟多个hash函数,当然这里不是用来解决冲突的。
和线性再探测(linearprobing)一样,Double hashing从一个hash值开始,重复向前迭代,直到解决冲突或者搜索完hash表。不同的是,double hashing使用的是另外一个hash函数,而不是固定的步长。
给定两个独立的hash函数h1和h2,对于hash表T和值k,第i次迭代计算出的位置就是:h(i, k) = (h1(k) + i*h2(k)) mod |T|。
对此,Leveldb选择的hash函数是:Gi(x)=H1(x)+iH2(x)
H2(x)=(H1(x)>>17) | (H1(x)<<15)
H1是一个基本的hash函数,H2是由H1循环右移得到的,Gi(x)就是第i次循环得到的hash值。【理论分析可参考论文Kirsch,Mitzenmacher2006】
在bloom_filter的数据的最后一个字节存放的是k_的值,k_实际上就是G(x)的个数,也就是计算时采用的hash函数个数。
8.3.2 BloomFilter参数
变量k_实际上就是模拟的hash函数的个数;
关于变量bits_per_key_,对于n个key,其hash table的大小就是bits_per_key_。它的值越大,发生冲突的概率就越低,那么bloom hashing误判的概率就越低。因此这是一个时间空间的trade-off。
对于hash(key),在平均意义上,发生冲突的概率就是1/ bits_per_key_。
它们在构造函数中根据传入的参数bits_per_key初始化。
bits_per_key_ = bits_per_key;
k_ =static_cast<size_t>(bits_per_key * 0.69); // 0.69 =~ ln(2)
if (k_ < 1) k_ = 1;
if (k_ > 30) k_ = 30;模拟hash函数的个数k_取值为bits_per_key_*ln(2),为何不是0.5或者0.4了,可能是什么理论推导的结果吧,不了解了。
8.3.3 建立BloomFilter
void CreateFilter(const Slice* keys, int n, std::string* dst) const
下面分析其实现代码,大概有如下几个步骤:
S1 首先根据key个数分配filter空间,并圆整到8byte。
size_t bits = n * bits_per_key_;
if (bits < 64) bits = 64; // 如果n太小FP会很高,限定filter的最小长度
size_t bytes = (bits + 7) / 8;// 圆整到8byte
bits = bytes * 8; // bit计算的空间大小
const size_t init_size =dst->size();
dst->resize(init_size +byt
