一、 简介
history
started by chad walters and jim
2006.11 G release paper on BigTable
2007.2 inital HBase prototype created as Hadoop contrib
2007.10 First useable Hbase
2008.1 Hadoop become Apache top-level project and Hbase becomes subproject
2008.10 Hbase 0.18,0.19 released
?
hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
?
HBase中的表一般有这样的特点:
1 大:一个表可以有上亿行,上百万列
2 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
3 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
?
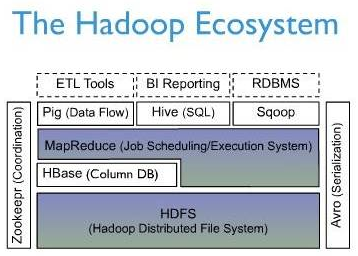
下面一幅图是Hbase在Hadoop Ecosystem中的位置。
二、 逻辑视图
?
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(row family)
| Row Key | column-family1 | column-family2 | column-family3 | |||
| column1 | column1 | column1 | column2 | column3 | column1 | |
| key1 | t1:abc t2:gdxdf |
? | t4:dfads t3:hello t2:world |
? | ? | ? |
| key2 | t3:abc t1:gdxdf |
? | t4:dfads t3:hello |
? | t2:dfdsfa t3:dfdf |
? |
| key3 | ? | t2:dfadfasd t1:dfdasddsf |
? | ? | ? |
t2:dfxxdfasd
? t1:taobao.com |
?
Row Key
与nosql数据库们一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
1 通过单个row key访问
2 通过row key的range
3 全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组。
存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
注意:
字典序对int排序的结果是1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整形的自然序,行键必须用0作左填充。
