利用数据库存储订单、通报和任务,构建高性能队列
日期:2014-05-16 浏览次数:20740 次
利用数据库存储订单、通知和任务,构建高性能队列
原文地址:http://www.codeproject.com/Articles/110931/Building-High-Performance-Queue-in-Database-for-st
作者:chszs,转载需注明。博客主页:http://blog.csdn.net/chszs
引言
到处都有队列。很多Web网站,经常可以看到使用队列来异步发送通知,比如email和SMS。电子商务网站常常使用队列来存储订单、处理订单以及实现订单的分发。工厂生产线的自动化系统也经常使用队列并行处理任务。队列是一种广泛使用的数据结构,有时它必须创建到数据库里,而不是使用专门的队列技术(比如MSMQ)。使用数据库技术来运行一个高性能且高可扩展性的队列对我们来说是一个巨大的挑战。而且当每天进出队列的记录达到数百万行时,队列的维护是很困难的。下面我将向你展示在设计类似队列表时常犯的设计错误以及如何使用简单的数据库功能实现队列的最大性能和扩展性。
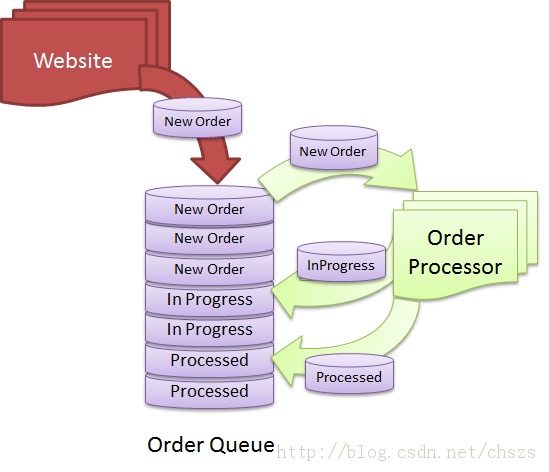
首先我们需要清楚在设计队列表时会遇到哪些挑战:
1)表的读写。
由于入队列和出队列是相互影响的,在高负载下可能会导致锁竞争、事务死锁、IO超时等等。
2)当多个接收者试图从同一队列读数据时,它们会随机地获取重复项,因而导致重复的处理过程。
你需要在队列上实现一些高性能的行锁定,以便让并发接受器不会接收相同的数据项。
3)队列表需要以某种顺序存储行以及以某种顺序读取行,这使得设计索引很棘手。
队列表并不总是遵守先进先出的,有时候顺序中的消息带有更高的优先级,无论这个消息是否入队列都要先处理它。
4)队列表需要以XML或二进制的形式序列化对象,这使得存储和重建索引很麻烦。
你不能在队列表中重建索引,因为它包含了文本或二进制字段。因此,每过一天,数据表会变得越来越慢,最后查询会超时,你不得不关闭服务并重建索引。
5)出队列的过程中,一批行数据被选中、被更新,然后返回数据。你需要一个"State"(状态)列来定义数据项的状态。出队列时,你只需选择某个状态的数据项。现在状态只有几种类型:PENDING(待定)、PROCESSING(处理中)、PROCESSED(已处理)、ARCHIVED(存档)。你不能在状态列上创建索引,因为不能提供足够的选择性,具有相同的状态的数据行有成千上万。因此,任何出队列操作都会导致集群的索引被重新扫描,这属于CPU和IO密集型操作,会产生锁竞争。
6)在出队列的过程中,你不能仅仅移除队列表的相关行,因为这很容易导致数据表产生存储碎片。而且,你还需要重新处理订单/任务/通知做N次操作以防止这些操作在第一次中失败。这意味着存储行数据需要更长的时间、索引会持续增长以及出队列越来越慢。
7)你必须归从入队表把处理过的数据项归档到不同的数据表或数据库,以保持主队列表的精简。这意味着需要移动大量的带有特定状态的数据行到另一个数据库。如此大的数据移动会频繁产生存储碎片,以至于降低入队列和出队列的性能。
8)你有24×7不间断的业务。你不能停止服务再归档大量的行数据。这意味者你必须在不影响入栈和出栈通信的情况下持续的归档行数据。
如果您已实现这样的队列表,你可能已经遇到了以上一个或多个的麻烦。本文将教你一些如何应对这些挑战的技巧,以及如何设计和维护一个高性能的队列表。
在SQL Server创建一个典型的队列
下面我们创建一个典型的队列表为例,看看它在并发负载时的是怎样工作的。
CREATETABLE [dbo].[QueueSlow](
[QueueID] [int] IDENTITY(1,1) NOT NULL,
[QueueDateTime] [datetime] NOT NULL,
[Title] [nvarchar](255) NOT NULL,
[Status] [int] NOT NULL,
[TextData] [nvarchar](max) NOT NULL
)ON [PRIMARY]
GO
CREATEUNIQUE CLUSTERED INDEX [PK_QueueSlow] ON [dbo].[QueueSlow]
(
[QueueID] ASC
)
GO
CREATENONCLUSTERED INDEX [IX_QuerySlow] ON [dbo].[QueueSlow]
(
[QueueDateTime] ASC,
[Status] ASC
)
INCLUDE( [Title])
GO
在队列表中,出队列使用了QueueDateTime作为排序顺序,以此模拟先进先出的算法或队列的优先级。QueueDateTime不一定是对象入队列的时间,而是对象被处理的开始时间。因此,时间最早的数据行会先被选出。TextData字段是一个很大的字符串字段,它存储有效载荷。
在此表中使用QueueDateTime字段作为非聚集索引,目的是在出队列期间使得使用QueueDateTime字段排序更快。
首先,我们先对这个表填充数据,插入4万行约500兆的数据,其中每行的有效载荷的大小互不相同。
setnocount on
declare@counter int
set@counter = 1
while@counter < @BatchSize
begin
insert into [QueueSlow] (QueueDateTime,Title, Status, TextData)
select GETDATE(), 'Item no: ' +CONVERT(varchar(10), @counter), 0,
REPLICATE('X', RAND() * 16000)
set @counter = @counter + 1
end
下面我们一次性出队列10个数据行。在出队列时,会根据QueueDateTime和Status = 0选出排在最前面的10行数据,并将其Status状态更新为1,表示该数据行正在被处理。在出队列的期间,我们不会从队列表中删除这些数据行,因为我们要确保这些数据行在终端接收失败时永远不会丢失。
CREATEproce
