Mysql 切分守则及其相应机制简介
日期:2014-05-16 浏览次数:21249 次
Mysql 切分规则及其相应机制简介
前段时间看了一下Mysql数据库切分方面的知识,感觉某些点还挺有技巧的,决定小小的对自己所看的知识点进行一下总结。
随着企业的不断发展,需要存储的数据不断加大,以往把数据放在单一的数据库中的做法越来越成为存取数的瓶颈,因此就对数据库提出了以下的一些要求:
1、为了降低单台数据库 负载,引入数据库切分。
2、考虑到大多数数据库操作大都“多读少写”,因此,在数据库中引入“读写分离”机制。
3、为了数据库容灾,在数据库中引入备库的思想。
基于以上需要mysql数据库可以从以下几方面入手进行改造:
一、数据库水平切分
考虑一个情况, 一个表中现在有5000w条数据,在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,5000w行数据建立索引的系统开销是不容忽视的。因此为了解决以上问题,我们引入了第一个数据切分的方式: 数据库内的水平切分。这种切分方式是 对数据通过一系列的切分规则,将数据分布到一个数据库的不同表中,比如将article分为article_001,article_002等子表,若干个子表水平拼合有组成了逻辑上一个完整的article表。但是这种方式仍然将读取限定在了一台数据库,因此由此产生了另外一种切分: 物理上的水平切分,即将数据分布到不同的DB服务器上,通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。
那通过哪些方法能够将数据库拆分呢,总结了下,主要有几下几点:
1、按号段分:即按照某一个字段的区间来分库、分表,如用户表,可按照Id为1——100的用户存放在 DB1,Id为101——200的用户存放在 DB2。这样做的优点是具有方便的迁移性,可以方便的将数据库进行拆分;但缺点是数据分布不均。
2、hash取模分:
将数据按照某种规则进行hash运算,结果作为存到哪个库、哪个表的依据。这种分库、分表的
优点是数据可以分布的很均匀;但这种方式的缺点同样突出,首先是数据迁移时会很麻烦,同时由于数据分配很均衡也就导致了数据并不能按照机器性能分摊。
3、在认证库中保存数据库配置:即创建一个中心库,存放了数据路由的规则,每条数据到底存放在什么位置,中心库中都能够有记录。这种方式优点是灵活性强,具有一对一的关系;但缺点是每次查询之前都要多一次查询,性能大打折扣。
二、数据库的读写分离策略
由于数据库大多是“多读少写”的,同时由于写数据存在锁表的机制,因此在数据库集群内可以采用“读写分离”的机制来提高性能。具体做法是:在数据库集群内部制定一台数据库为master,另外几台为slave,并都与master通信,对数据库所有的写操作都在master端发生,而其他slave与master共同来负责读的任务,当master端写完数据后将数据传递给slave(其实是slave向master请求),这样就能做到数据的一致性。利用这种机制分散了对数据库读的负载,同时也能够控制写数据时锁表对数据库的影响。其中把数据从master端复制到slave端的操作由mysql的replication机制保证。
mysql的replication机制:
replication机制的步骤如下图所示:
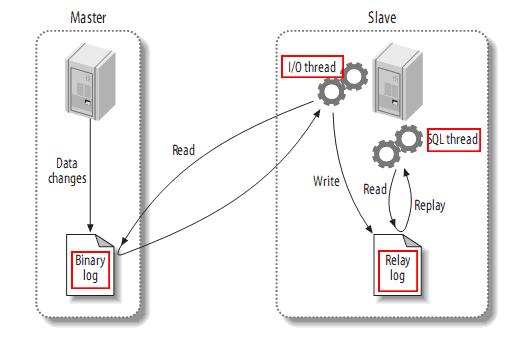
1、
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
