簇索引并不是索引的一种分支类型,更确切的说,它是数据存储的一种方式.它和普通索引仅仅在实现上有着不同的区别,Innodb的簇索引实际是将索引和数据存储在同一B-Tree中的存储结构.当某表中含有簇索引,表中的数据实际是存储在索引树的叶节点中.所谓的"簇",意思着包含相邻键的数据也存储在相邻的区域中.每张表只能存在唯一一个簇索引,因为你总不能把一份数据同时存储在两个地方.因为索引的实现是各个存储引擎实现的一部分,不是所有的存储引擎都只是簇索引.目前有solidDb和Innodb对簇索引提供了支持.我们这里主要对Innodb的簇索引进行讨论,但是其中的一些概念都适用于所有支持簇索引的存储引擎.
?
下图显示了簇索引的数据存储结构.注意,每个叶子节点包含的都是完整的数据行,而不像是内节点,仅仅包含的是被索引的列,在这个图里面,被索引的列是整型值.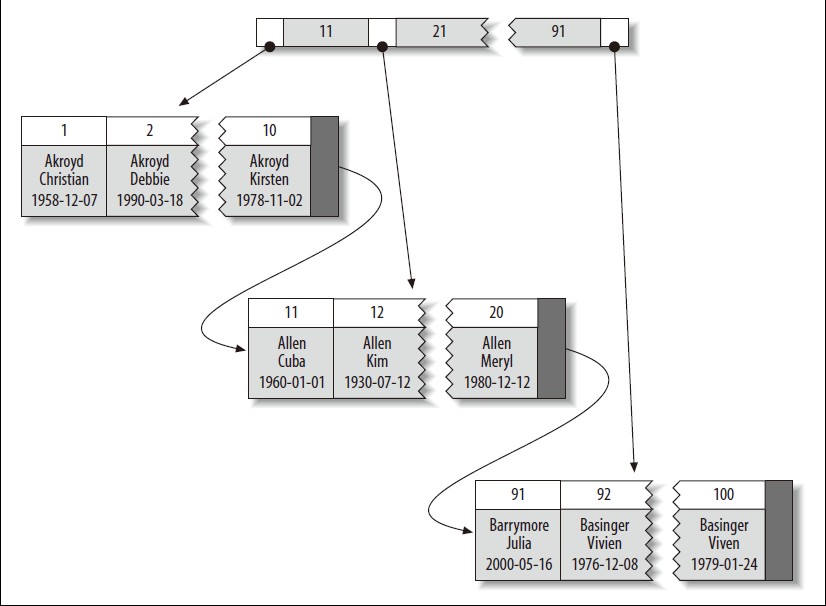
?有些数据库服务器端会让你选择簇索引的索引列,但是目前的Innodb默认只会对表主键进行簇索引.意味着上图的整型值即为为主键.如果你的表中没有主键,Innodb会尝试用一个唯一非空字段作为其簇索引的索引列,如果没有这样的字段,Innodb会为你的表结构定义一个隐藏主键而对其进行簇索引.Innodb的簇索引以内存页为存储单元,所以,相邻索引值可能会存储在相隔很远的内存页中.
?
簇索引能提高检索效率,同样地也会带来其他的性能问题,所以,你应该对其进行慎重考虑,特别是你将一种存储引擎更改为Innodb时.簇索引有如下优点:
- 簇索引能将可能的逻辑相关数据存储在一起.例如,为了实现一个邮箱管理器,你能对user_id进行簇索引,这样你就能对同一用户的所有邮件进行检索,不管这些邮件的存储时间是进还是远,如果没有对user_id建立主键关系,那么这样的一个需求可能就会引起很大的磁盘io问题.
- 数据访问更加快速.簇索引不仅仅存储索引值,也同时存储了数据值,所以通过索引检索数据往往比寻址更加迅捷.
- 能很轻松的获取主键,从而实现索引覆盖查询
