求关于下部的查询语句的优化方案
日期:2014-05-17 浏览次数:21081 次
求关于下面的查询语句的优化方案
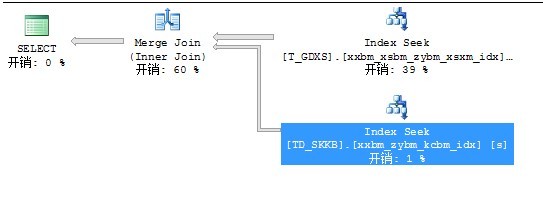
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
/*
(593527 行受影响)
表 'Worktable'。扫描计数 69,逻辑读取 113303 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'TD_SKKB'。扫描计数 1,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'T_GDXS'。扫描计数 1,逻辑读取 353 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 2375 毫秒,占用时间 = 7973 毫秒。
*/
说明:表td_skkb有1.5万条数据左右,表t_gdxs有250万条数据左右 满足条件的xx_bm='0101'的大概有5.5万条数据
我之前的索引:
create index xxbm_zybm_kcbm_idx on td_skkb(xx_bm,kc_bm,zy_bm)
go
create nonclustered index xxbm_xsbm_zybm_xsxm_idx on t_gdxs(xx_bm,zy_bm)include (xs_bm,xs_xm)
go
没创建这两个索引之前耗时16s,现在耗时8s这任然是不能接受的
------解决方案--------------------
你们这些高手啊,没事干了是不?
------解决方案--------------------
围观一下
------解决方案--------------------
select g.xs_bm,g.xs_xm,g.xx_bm,s.zy_bm,s.kc_bm
from td_skkb s inner join (select * from t_gdxs where xx_bm='0101') g
on g.xx_bm=s.xx_bm and g.zy_bm=s.zy_bm
------解决方案--------------------

------解决方案--------------------
打酱油的
------解决方案--------------------
为什么不在查询条件上建立聚集索引
CREATE INDEX index_name ON t_gdxs (zy_bm,zy_bm)
CREATE CLUSTERED INDEX INDEX_name ON t_gdxs(xx_bm)
我测试过,聚集索引的选择可能会影响到索引的碎片,
但是在查询条件上建立聚集索引,与造成的碎片相比,是值得的。
------解决方案--------------------
可以了吧,还能优化吗,围观一下
------解决方案--------------------
on ...(xx_bm,zy_bm) include(....) ?
------解决方案--------------------
围观
------解决方案--------------------
lu guo
------解决方案--------------------
select
g.xs_bm,
g.xs_xm,
g.xx_bm,
s.zy_bm,
s.kc_bm
from
td_skkb s
inner join
t_gdxs g
on
g.xx_bm=s.xx_bm
and g.zy_bm=s.zy_bm
where
g.xx_bm='0101'
go
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
/*
(593527 行受影响)
表 'Worktable'。扫描计数 69,逻辑读取 113303 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'TD_SKKB'。扫描计数 1,逻辑读取 5 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'T_GDXS'。扫描计数 1,逻辑读取 353 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 2375 毫秒,占用时间 = 7973 毫秒。
*/
说明:表td_skkb有1.5万条数据左右,表t_gdxs有250万条数据左右 满足条件的xx_bm='0101'的大概有5.5万条数据
我之前的索引:
create index xxbm_zybm_kcbm_idx on td_skkb(xx_bm,kc_bm,zy_bm)
go
create nonclustered index xxbm_xsbm_zybm_xsxm_idx on t_gdxs(xx_bm,zy_bm)include (xs_bm,xs_xm)
go
没创建这两个索引之前耗时16s,现在耗时8s这任然是不能接受的
------解决方案--------------------
你们这些高手啊,没事干了是不?
------解决方案--------------------
围观一下
------解决方案--------------------
select g.xs_bm,g.xs_xm,g.xx_bm,s.zy_bm,s.kc_bm
from td_skkb s inner join (select * from t_gdxs where xx_bm='0101') g
on g.xx_bm=s.xx_bm and g.zy_bm=s.zy_bm
------解决方案--------------------
------解决方案--------------------
打酱油的
------解决方案--------------------
为什么不在查询条件上建立聚集索引
CREATE INDEX index_name ON t_gdxs (zy_bm,zy_bm)
CREATE CLUSTERED INDEX INDEX_name ON t_gdxs(xx_bm)
我测试过,聚集索引的选择可能会影响到索引的碎片,
但是在查询条件上建立聚集索引,与造成的碎片相比,是值得的。
------解决方案--------------------
可以了吧,还能优化吗,围观一下
------解决方案--------------------
on ...(xx_bm,zy_bm) include(....) ?
------解决方案--------------------
围观------解决方案--------------------
lu guo
------解决方案--------------------
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
