详解Firefox 3.5的新JavaScript发动机-TraceMonkey
日期:2014-05-16 浏览次数:20595 次
本文作者为David Mandelin ,──Mozilla JavaScript团队工作人员。
?
Firefox 3.5拥有一个全新的JavaScript引擎,叫做TraceMonkey,在该引擎上跑JS应用要比Firefox 3快到3-4倍,从而为现有的网络应用加速。这篇文章大致的描述一下在TraceMonkey中包括的重要部件,以及他们是如何加速JavaScript 的。同样,在了解这些之后,你也就能知道什么样的网络应用通过TraceMonkey能够获得最大的提速,以及怎么样来写您的程序获得更大的性能提高。
为什么提速JS很难:动态类型
类似于JavaScript和Python这样的高级动态语言通常使得编程效率非常高,但是同类似Java或者C这样的静态语言相比,他们要慢一些。按照经验来说,一个JS程序通常要比同等的Java程序慢10倍。
像JS这样的动态语言比像Java或者C这样的静态语言慢主要有两个原因。第一个原因是在动态语言中,通常不太容易在执行之前知道值的类型信息。因此,语言本身必须使用一个通用的格式存储所有的值并且使用通用的操作来处理他们。
相反,在Java中,程序员声明变量和方法的类型,编译器可以在运行之前就知道这些值的类型。编译器可以使用特定的格式和操作来处理这些值,而这个过程要比通用的格式和操作快很多。下面,我会把这类操作叫做类型特定 处理。
动态语言运行慢的第二个原因是,动态脚本语言通常实现为解释器,也就是由解释器执行;而静态语言通常被编译为原生代码。解释器可以很容易的构造,但 是他们需要额外的运行时间来处理跟踪他们的内部状态。像Java这样的语言会被编译成机器语言,基本上是不需要内部运行状态跟踪的。
让我们用一张图片来描述的更具体。这里有一个简单的加法的分解动作示意图,我们来计算一下:a + b
,这里a
和b
均为整数。首先,我们忽略最右边的柱状图,集中在Firefox 3的JavaScript解释器和Java JIT执行效率的比较上。每个纵列都表示在某种语言上这个加法运算要做的分解动作。时间从上到下进行,每个不同颜色的盒子高度基本表示进行该分解动作需要的时间。
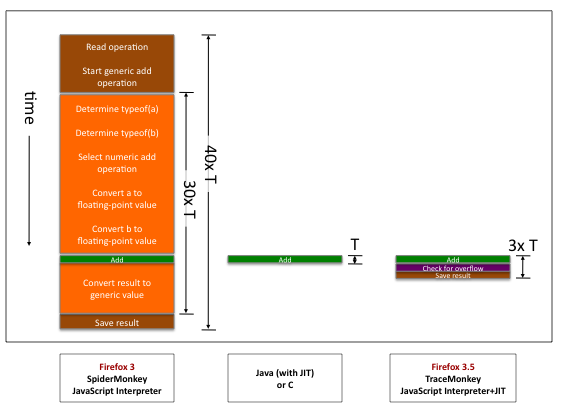
在中间,Java简单的运行一条机器指令:“加”命令,运行时间为T(一个处理器周期)。因为Java编译器预先知道运算值为标准的机器整数类型,她可以直接使用标准的整数加法机器指令。完了。
在左边,SpiderMonkey(FF3中的JS解释器)需要大概40个T。棕色部分的盒子部分为整个解释器的开销:解释器需要读取加操作,然后跳到解释器的通用加操作代码部分。橘色的盒子部分表示由于解释器不知道运算值的类型造成的额外工作。解释器需要解开a
和b
的通用描述格式,判断出他们的类型,选择特定的加法运算,把值转换为正确的类型,加法进行完之后,还需要把结果转换为通用的描述格式。
上面的图表显示,使用解释执行要比编译器慢一些,而使用不带任何类型信息的解释执行要慢很多。如果我们希望JS能够被运行的快一些,根据Amdahl定律 ,我们需要做点关于类型的事情。
通过跟踪获得类型
在TraceMonkey中,我们的目标是没有蛀牙,不对,我们的目标是编译出类型特定的代码。为了实现这个目标,TraceMonkey需要知道 变量的类型。但是JavaScript本身是没有类型的,而我们前面也说过JS引擎基本上是无法在运行前知道类型的,但是我们还要在运行之前编译出本地代 码,貌似无路可走了。
让我们换个角度来看这个问题。如果我们让程序在解释器中先跑一段,那么引擎就可以直接觉察 到数值的类型了不是。然后,引擎可以使用这些类型来编译产生更快的类型特定的代码。最后,引擎就可以开始运行这些类型特定的代码,于是就运行的更快了~
这个想法还有几个关键的细节。首先,当程序运行时,即便有很多的if语句和其他的程序分支,他始终在其中一个分支上。所以,引擎不太有机会觉察到方法中所有数值的类型──引擎通过路径来观察数值,我们称之为轨迹 Traces 。因此,标准的编译器是对整个方法或者过程进行编译,而TraceMonkey是针对轨迹进行编译。运行期轨迹编译有个好处是在轨迹上的函数调用是内联inline的,这使得轨迹上的函数调用非常的快。
第二,编译类型特定的代码是占用运行时间的。如果一块代码仅仅会运行一次或少量的几次──这在网页代码中比较常见──他可能会占用更多的时间来编译和运行反而可能还不如直接在解释器里面运行来的快了。所以,他应该只去编译热代码 (被运行很多次的代码)。在TraceMonkey中,我们通过跟踪循环来安排热代码。TraceMonkey开始在解释器中运行所有代码,并开始为循环记录轨迹中的热代码。
仅跟踪热循环代码结果之一就是:只运行几次的代码并不会在TraceMonkey中得到提速。而这通常不会影响实际运行效果,因为仅运行几次的代码通常很快就完事了,你可能都不会注意到他。另一个结果是那些不热的循环代码基本上不被运行,也不会被编译,从而节省编译时间。
最后,上面我们提到TraceMonkey是通过观察执行过程来判断数值类型,基本上算是事后诸葛亮的做法,可能并不能保证将来的结果──更准缺点 说算是事中诸葛亮:下次这部分代码被运行时,数值类型可能变了,或者第500次的时候开始变了也说不定。当我们已经产生好针对数字类型编译的代码之后,值 变成字符串类型了,那就糟糕了。所以,TraceMonkey必须在编译代码中加入类型检查。如果没有通过检查,TraceMonkey必须离开当前轨 迹,使用新类型重新编译这个轨迹上的代码。这就意味着拥有很多分支或者类型经常改变的代码在TraceMonkey中不一定能得到多少性能上的提高,因为 他需要花费运行时间来编译多出来的轨迹或者从这个轨迹跳到那个等等。
TraceMonkey操作起来~
现在,我们通过一些示例来看一下TraceMonkey的实际操作情况:我们这里要完成的工作是把从1到N的整数都加到一个起始值上:
function addTo( a, n) { for ( var i = 0 ; i < n; ++ i) a = a + i; return a; } ?
