java并发学习之5:读JSR133笔记
日期:2014-05-16 浏览次数:20698 次
java并发学习之五:读JSR133笔记
在写线程池的时候,遇到了很多的问题,特别是happen-before应该怎么去理解,怎么去利用,还有reorder,哪些操作有可能会被reorder?在这一点上,发现其实《concurrency in practice》也没描述得太清晰。
在网上搜了一遍,发现JSR133的faq相对而言,还算稍微解释了一下,发现JSR133其实也就40多页,所以也就顺带看了一遍,因为大部分的内容都比较简单(越往后看发现越复杂~),但是里面的定义比较难理解,所以只记录了定义和一些个人认为比较重要的地方,或者比较难理解的地方
这里是阅读笔记,以备以后查阅
前言部分
1.下面的网站提供了附加的信息,帮助进一步地理解JSR133
http://www.cs.umd.edu/~pugh/java/memoryModel/
2.在JLS中很可能需要JVM(TM)实现的两个原始的定义的改变:
一.introduction
3.JSR133并不是描述多线程程序应该怎么去执行,而是描述多线程程序允许怎么去显示的,他包括一些规则,这些规则定义了一个被多线程更新的共享变量的值,是否是可见的。(比如读一个共享变量的值,根据规则,应该显示的是什么)
4.还是synchronized的问题,该问题在之前的文章中也提到过,在方法上的时候,它锁的是this,如果是静态方法,那么锁的是方法所在类的class
二.Incorrenctly Synchronized Programs Exhibit Surprising Behaviors
5.不合适的同步(improperly synchronized):(注:并不意味着错误)
三.Informal Semantics
6.正确的同步(correct synchronization)(严格地保证多线程访问的正确性,但吞吐率很低的)
理解一个程序是否被正确地同步,有两个关键点:
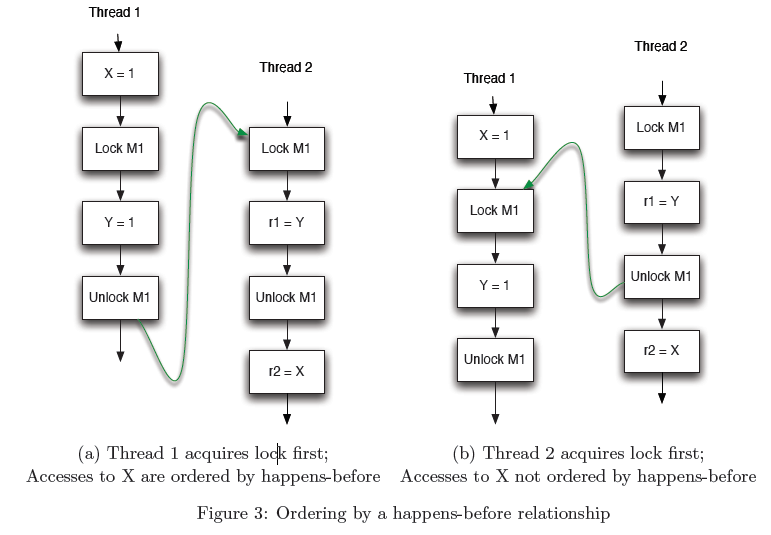
这里有一个很有意思的图片,可能对别人没太多的意义,但对我自己而言,真是解释了不少以前的迷惑,最主要是第二幅图片的,之前有一个误解:数据只有在同步块中,而另一个线程必须也进入一个相同的锁的同步块中,才能保证其可见性。但其实不是这样的,只要能够保证顺序一致性,就是可见的,如图a
7.final field
在这一节,并没有解释final field是怎么保证其同步的(根据之前的理解,如果有final field,应该在对象的构造完成之后做了一些事来保证同步,但到底做了什么事?还得看下文第9章),只是定义了final field在构造完成后,就不会再改变,所以只需要在构造器中,保证其没有escape,就可以正确地在并发环境中无限制地使用了。
四.What is a Memory Model?
8.存储模型(memory model)的定义:
一个存储模型(memory model)描述的是,给定一个程序和这个程序的执行轨迹(trace),就可以判断这个执行轨迹(trace)是否是合法的。在Java程序语言中,存储模型(memory model)是这样工作的:检查在运行轨迹(trace)中的每个读,并且根据一定的规则,校验这个读观察到的写是否是有效的。
存储模型(memory model)描述一个程序可能的举止。一个存储模型(memory model)实现可以随意地产生任何的代码(像reorder,删除一些没必要的同步),只要所有的程序运行结果可以根据存储模型(memory model)来预测。
9.JVM做的一些事
当我们说读(read),我们只是说的是一些这样的动作:如读一些fields或者数组。其他操作的语义,像读一个数组的长度,执行一个类型转换(checked casts),或者调用一个虚拟的方法(invocations of virtual methodds,个人的理解应该是调用接口的一个方法),是不会直接受数据竞争的影响的。JVM的实现保证了数据竞争不会导致错误的举动,像返回一个错误的数组长度,或者调用虚拟方法的错误(在竞争的数据中,应该是可能发生的)。
五.Definitions
10.共享变量/堆内存(Shared variables/Heap memory):
能够在线程间被共享的内存被叫做共享内存或者堆内存。所有的实例域(instance fields),静态域(static fileds)和数组都被存在堆内存。我们用变量(vari
在写线程池的时候,遇到了很多的问题,特别是happen-before应该怎么去理解,怎么去利用,还有reorder,哪些操作有可能会被reorder?在这一点上,发现其实《concurrency in practice》也没描述得太清晰。
在网上搜了一遍,发现JSR133的faq相对而言,还算稍微解释了一下,发现JSR133其实也就40多页,所以也就顺带看了一遍,因为大部分的内容都比较简单(越往后看发现越复杂~),但是里面的定义比较难理解,所以只记录了定义和一些个人认为比较重要的地方,或者比较难理解的地方
这里是阅读笔记,以备以后查阅
前言部分
1.下面的网站提供了附加的信息,帮助进一步地理解JSR133
http://www.cs.umd.edu/~pugh/java/memoryModel/
2.在JLS中很可能需要JVM(TM)实现的两个原始的定义的改变:
- volatile变量的语义被加强了,以前的语义是允许自由地被reorder的
- final的语义也被加强了,现在可以不需要显性得同步,就可以获得线程安全的不变性。这可能需要在含有设置final field的构造函数的结尾,加入一些存储屏障的步骤
一.introduction
3.JSR133并不是描述多线程程序应该怎么去执行,而是描述多线程程序允许怎么去显示的,他包括一些规则,这些规则定义了一个被多线程更新的共享变量的值,是否是可见的。(比如读一个共享变量的值,根据规则,应该显示的是什么)
4.还是synchronized的问题,该问题在之前的文章中也提到过,在方法上的时候,它锁的是this,如果是静态方法,那么锁的是方法所在类的class
二.Incorrenctly Synchronized Programs Exhibit Surprising Behaviors
5.不合适的同步(improperly synchronized):(注:并不意味着错误)
- 一个线程写
- 另一个线程读
- 读和写没有用synchronized来保证顺序
三.Informal Semantics
6.正确的同步(correct synchronization)(严格地保证多线程访问的正确性,但吞吐率很低的)
理解一个程序是否被正确地同步,有两个关键点:
- 冲突的访问(Conflicting Accesses):对同一个共享域或共享数组的多个访问,并且这些访问至少有一个是写,就说明有冲突。
- Happens-Before关系 :如果一个动作happens-before另一个,前者对后者是可见的,并且在执行顺序上也会在后者的前面。这点必须强调一下:一个happens-before关系,并不是暗示这些动作在java平台实现中,必须按这样的顺序去执行。(这里并不是很理解,难道也会是一个幻象?)原话是这样的:It should be stressed that a happens-before relationship between two actions does not imply that those actions must occur in that order in a Java platform implementation.
Happens-before关系最主要是强调并定义了两个有竞争的动作之间的顺序(当数据竞争出现时)
happens-before的规则包括:(注意,这些动作在直觉上是本该如此的,但在多线程中,就不一定了,所以才有这些规则)
a.在这个线程中,每个动作happens-before每个之后的动作。
b.一个对固有锁(monitor)的unlock操作happens-before每个之后的对monitor的lock操作。
c.一个对volatile filed的写happens-before每个之后的对该volatile的读(注意,这里没有线程的限制)
d.一个对线程的start()的调用(call)happens-before该线程中任何动作。
e.在线程中的所有动作happens-before任何其他线程成功地调用对该线程的join()返回
f.如果a happens-before b,b happens-before c,那么a happens-before c,即具有传递性
这里有一个很有意思的图片,可能对别人没太多的意义,但对我自己而言,真是解释了不少以前的迷惑,最主要是第二幅图片的,之前有一个误解:数据只有在同步块中,而另一个线程必须也进入一个相同的锁的同步块中,才能保证其可见性。但其实不是这样的,只要能够保证顺序一致性,就是可见的,如图a
7.final field
在这一节,并没有解释final field是怎么保证其同步的(根据之前的理解,如果有final field,应该在对象的构造完成之后做了一些事来保证同步,但到底做了什么事?还得看下文第9章),只是定义了final field在构造完成后,就不会再改变,所以只需要在构造器中,保证其没有escape,就可以正确地在并发环境中无限制地使用了。
四.What is a Memory Model?
8.存储模型(memory model)的定义:
一个存储模型(memory model)描述的是,给定一个程序和这个程序的执行轨迹(trace),就可以判断这个执行轨迹(trace)是否是合法的。在Java程序语言中,存储模型(memory model)是这样工作的:检查在运行轨迹(trace)中的每个读,并且根据一定的规则,校验这个读观察到的写是否是有效的。
存储模型(memory model)描述一个程序可能的举止。一个存储模型(memory model)实现可以随意地产生任何的代码(像reorder,删除一些没必要的同步),只要所有的程序运行结果可以根据存储模型(memory model)来预测。
9.JVM做的一些事
当我们说读(read),我们只是说的是一些这样的动作:如读一些fields或者数组。其他操作的语义,像读一个数组的长度,执行一个类型转换(checked casts),或者调用一个虚拟的方法(invocations of virtual methodds,个人的理解应该是调用接口的一个方法),是不会直接受数据竞争的影响的。JVM的实现保证了数据竞争不会导致错误的举动,像返回一个错误的数组长度,或者调用虚拟方法的错误(在竞争的数据中,应该是可能发生的)。
五.Definitions
10.共享变量/堆内存(Shared variables/Heap memory):
能够在线程间被共享的内存被叫做共享内存或者堆内存。所有的实例域(instance fields),静态域(static fileds)和数组都被存在堆内存。我们用变量(vari
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
