Java开展HTML数据采集:浅谈强大的group正则
日期:2014-05-17 浏览次数:21246 次
?
简? 介
作为全球运用最广泛的语言,Java 凭借它的高效性,可移植性(跨平台),代码的健壮性以及可强大的可扩展性,深受广大应用程序开发者的喜爱. 作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而且正则表达式的掌握能力也是那些高级程序员的开发功底之体现,做一名合格的网站开发 的程序员(尤其是做前端开发),正则表达式是必备的。
最近,由于一些需要,用到了java和正则,做了个的足球网站的数据采集程序,由于是第一次做关于java的html页面数据采集,必然在网上查找 了很多资料,但是发现运用如此广泛的java在使用正则做html采集方面的(中文)文章是少之又少,都是简单的谈了下java正则的概念,没有真正用在 实际网页html采集,所以实例教程更是寥寥无几(虽然java有它自己的Html Parser,而且十分强大),但个人觉得作为如此深入人心的正则表达式,理应有其相关的java实例教程,而且应该很多很全.于是在完成java版的 html数据采集程序之后,本人便打算写个关于正则表达式在java上的html页面采集,以便有相关兴趣的读者更好的学习。
关于group正则
说到正则表达式是如何帮助java进行html页面采集,这里简要需要提一下正则表达式中的group方法:
?
public static void main(String[] args){
//Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
//匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
//第2个正则是用于匹配标题 SoFlash的
//第3个正则用于匹配日期
/*这里只用了一条语句便把url,标题和日期全部给匹配出来了*/
Pattern p = Pattern.compile( "='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})" );
String s = "<a href='www.cnblogs.com/longwu'>SoFlash-12.22.2011</a>" ;
Matcher m = p.matcher(s);
while (m.find()){
//通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println( "打印出url链接:" +m.group( 1 ));
System.out.println( "打印出标题:" +m.group( 2 ));
System.out.println( "打印出日期:" +m.group( 3 ));
System.out.println();
}
System.out.println( "group方法捕获的数据个数:" +m.groupCount()+ "个" );
}
?
?
?
打印出url链接:www.cnblogs.com/longwu
打印出标题:SoFlash
打印出日期:12.22.2011
group方法捕获的数据个数:3个
想了解更多的朋友请看 JAVA 正则表达式 (超详细)
如果之前没有学过正则的可以看看这个 正则表达式的元字符匹配
好了 group方法介绍完了 我们来简单的使用下 group采集某个足球网站页面的数据
页面链接:http://www.footballresults.org/league.php?all=1&league=EngPrem
首先我们读取整个html页面,并打印出来 代码如下:
?
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org/league.php?all=1&league=EngPrem" ;
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/8186caf4f61fb7360b4c6547.html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog_44a05959010004il.html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8" ); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null ) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
?
?
打印出来的结果 是整个html页面的源代码 (部分截图如下)

到这里,数据已经成功采集下来了,当然 我们想要的并不是整个html源代码,我们需要的是网页上的比赛数据。
首先 我们分析下 html源代码结构 来到http://www.footballresults.org/league.php?all=1&league=EngPrem 页面
右键该页面 点击 ‘查看源文件’ 如图:
 ?
?
我们来看看 其内部的html代码结构 以及我们需要的数据
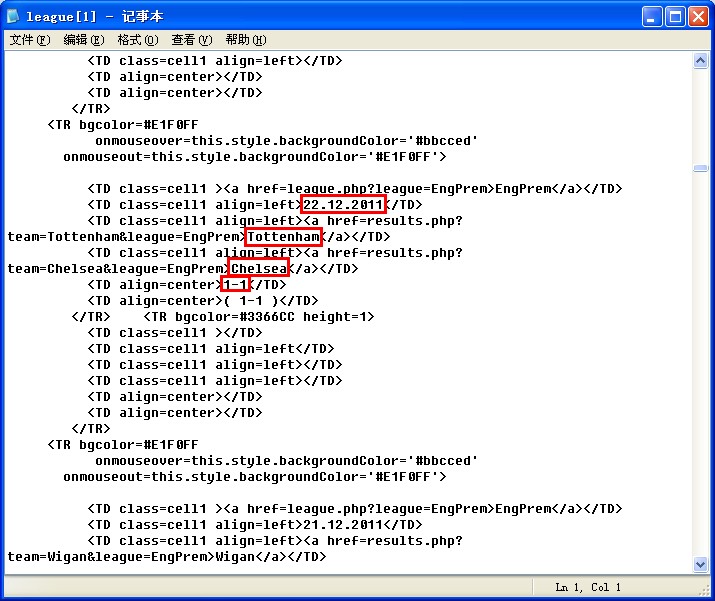 ?
?
其对应的页面数据
