下亿行文本怎么高效查询
日期:2014-05-17 浏览次数:21332 次
上亿行文本如何高效查询?
由于在开始的时候脑子里面有点想法 所以先自己动手做了一下再来问
是这样的 一个文本文件上亿行 写一个程序在里面查询对应的行
文本文件的每一行是 "Key-Value" 的形式
而Key是数字的字符串形式 是1 - 9 开头的无重复key 且在 int.MaxValue 内
现在要求给出 key 查找出key哪一行的数据 也就是 key - value 都查询出来
由于文件只用作查询 所以不用考虑增删改
我自己动手做了一下 由于现在完整文件不在我这里 我这里只有从文件切下来的200M 有八百多万行
自己写的那个程序针对这 八百万行 还算乐观 不知道对于完整的2G多的文件是啥效果
所以想请教一下 有这方面经验的人士 一般遇到这样的情况你们怎么处理
我是分了三大部
第一拆分文件:
先创建9个文本文件【1 - 9.txt】然后遍历文件每一行将取出每一样第一个字符 根据情况放入9个文本中
然后还有一个 int[9] 用做在遍历的时候保存每个文本文件当前有多少行数
然后遍历完成 将 int[9] 里面保存的每个文件的行数也写入到一个文件中 lines.txt
第二创建索引:
我定义了一个结构
然后分别读取【1 - 9.txt】每个文件对应的行数 lineNumber 在 lines.txt 中可以得到 然后可以创建对应的
LineOffset[] offset = new LineOffset[lineNumber] 对每个文本文件进行遍历 遍历每一行的时候 把key取出来 给offset[i] 然后把在文件中的偏移也计算出来
遍历完的时候 然后对 offset 根据key用了一个 归并排序 然后将排好序的offset写入文件 x_index.idx
第三整合文件: 这个还没有做
然后查询的时候 就可以把要查询的key的首字符 取出来然后去找 对应的 x_index.idx 因为文件里面的key是排好序的 所以直接 二分查找到key然后取出 在文件中的 偏移位置 然后打开对应文件直接通过偏移位置读取
这个是我查询的代码
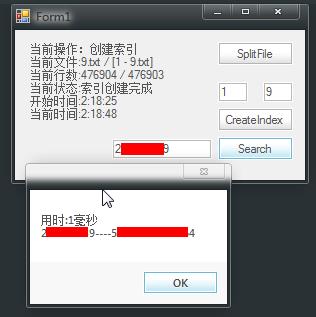
上面的时间 根据情况不定 对于同一个key有时候 是1毫秒 有时候是10+毫秒
那个 拆分文件 和创建索引 可能用了 一分多钟时间 不知道这两部对 完整的文件操作的时候 会用多少时间
总感觉自己的思路有些拼凑 想知道一些对处理大文件有经验的人会怎么做
------解决方案--------------------
没有看你后边的描述(我觉得没有必要),可能跟你的设计有重复。既然
由于在开始的时候脑子里面有点想法 所以先自己动手做了一下再来问
是这样的 一个文本文件上亿行 写一个程序在里面查询对应的行
文本文件的每一行是 "Key-Value" 的形式
而Key是数字的字符串形式 是1 - 9 开头的无重复key 且在 int.MaxValue 内
现在要求给出 key 查找出key哪一行的数据 也就是 key - value 都查询出来
由于文件只用作查询 所以不用考虑增删改
我自己动手做了一下 由于现在完整文件不在我这里 我这里只有从文件切下来的200M 有八百多万行
自己写的那个程序针对这 八百万行 还算乐观 不知道对于完整的2G多的文件是啥效果
所以想请教一下 有这方面经验的人士 一般遇到这样的情况你们怎么处理
我是分了三大部
第一拆分文件:
先创建9个文本文件【1 - 9.txt】然后遍历文件每一行将取出每一样第一个字符 根据情况放入9个文本中
然后还有一个 int[9] 用做在遍历的时候保存每个文本文件当前有多少行数
然后遍历完成 将 int[9] 里面保存的每个文件的行数也写入到一个文件中 lines.txt
第二创建索引:
我定义了一个结构
struct LineOffset{
public uint Key; //保存key
public long Offset; //保存对应key在文件中的偏移
}
然后分别读取【1 - 9.txt】每个文件对应的行数 lineNumber 在 lines.txt 中可以得到 然后可以创建对应的
LineOffset[] offset = new LineOffset[lineNumber] 对每个文本文件进行遍历 遍历每一行的时候 把key取出来 给offset[i] 然后把在文件中的偏移也计算出来
遍历完的时候 然后对 offset 根据key用了一个 归并排序 然后将排好序的offset写入文件 x_index.idx
第三整合文件: 这个还没有做
然后查询的时候 就可以把要查询的key的首字符 取出来然后去找 对应的 x_index.idx 因为文件里面的key是排好序的 所以直接 二分查找到key然后取出 在文件中的 偏移位置 然后打开对应文件直接通过偏移位置读取
这个是我查询的代码
FileStream fs = new FileStream("Files\\" + str[0] + "_index.idx", FileMode.Open);
long len = fs.Length / 12 - 1; //key + offset = 12字节
uint low = 0;
uint high = (uint)len;
byte[] byKey = new byte[4];
byte[] byAddr = BitConverter.GetBytes((long)-1);
while (low <= high) {
uint mid = (low + high) / 2;
fs.Seek(mid * 12, SeekOrigin.Begin);
fs.Read(byKey, 0, 4);
uint key = BitConverter.ToUInt32(byKey, 0);
if (key == num) {
fs.Read(byAddr, 0, 8);
break;
}
if (num < key)
high = mid - 1;
else
low = mid + 1;
}
fs.Close();
long addr = BitConverter.ToInt64(byAddr, 0);
if (addr < 0) { MessageBox.Show("Not Found"); return; }
StreamReader reader = new StreamReader("Files\\" + str[0] + ".txt");
reader.BaseStream.Seek(addr, SeekOrigin.Begin);
上面的时间 根据情况不定 对于同一个key有时候 是1毫秒 有时候是10+毫秒
那个 拆分文件 和创建索引 可能用了 一分多钟时间 不知道这两部对 完整的文件操作的时候 会用多少时间
总感觉自己的思路有些拼凑 想知道一些对处理大文件有经验的人会怎么做
查询
大文件
------解决方案--------------------
没有看你后边的描述(我觉得没有必要),可能跟你的设计有重复。既然
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
