解析html网页,该怎么解决
日期:2014-05-17 浏览次数:20728 次
解析html网页
各位,我要读取个纯html页面,获取里面的内容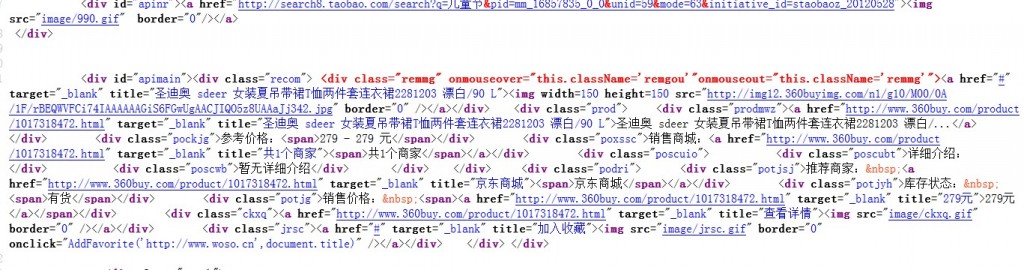 里面的东西我都要,存到数据库里,用正则太麻烦,而且东西可能会变的,有没有其他的方式,类似搞xml的?谢谢各位了
里面的东西我都要,存到数据库里,用正则太麻烦,而且东西可能会变的,有没有其他的方式,类似搞xml的?谢谢各位了
------解决方案--------------------
正则最简单,用其它办法更麻烦
------解决方案--------------------
首先实例化一个HtmlDocument
HtmlDocument document = new HtmlDocument();
然后HtmlDocument 有Load方法和LoadHtml方法,分表从Stream加载和文本中加载。你用WebRequest获取到资源,解析就行了。关键要学会XPath表达式。
各位,我要读取个纯html页面,获取里面的内容
里面的东西我都要,存到数据库里,用正则太麻烦,而且东西可能会变的,有没有其他的方式,类似搞xml的?谢谢各位了
html
数据库
------解决方案--------------------
正则最简单,用其它办法更麻烦
------解决方案--------------------
首先实例化一个HtmlDocument
HtmlDocument document = new HtmlDocument();
然后HtmlDocument 有Load方法和LoadHtml方法,分表从Stream加载和文本中加载。你用WebRequest获取到资源,解析就行了。关键要学会XPath表达式。
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
