Linux内存储器管理中内存的组织及主要数据结构分析(pg_data_t&&page&&zone)
日期:2014-05-16 浏览次数:21146 次
Linux内存管理中内存的组织及主要数据结构分析(pg_data_t&&page&&zone)
在讲解内核中用于组织内存的数据结构之前,考虑到术语不总是容易理解,所以先来看看几个概念。我们首先考虑NUMA系统,这样,在UMA系统上介绍这些概念就非常容易了。
下图给出内存划分的图示:
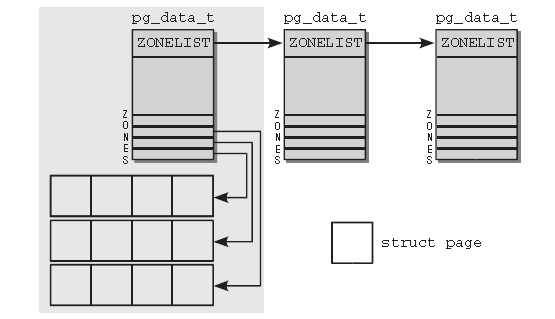
首先,内核划分为结点。每个结点关联到系统中的一个处理器,在内核中表示为pa_data_t的实例(稍后定义该数据结构)。各个结点又划分为内存域,是内存的进一步细分。例如,对可用于(ISA设备的)DMA操作的内存区是有限制的。只有钱16MB适用,还有一个高端内存区无法直接映射,在二者之间是通用的“普通”内存区。内核引入下列常量来枚举系统中的所有内存域:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,//标记适合DMA的内存域。该区域的长度依赖于处理器的类型。在IA-32计算机上,一般的限制是16MB,这是由古老的ISA设备强加的边界,但更现代的计算机也可能受这一限制的影响
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,//标记了使用32位地址字可寻址、适合DMA的内存域。显然只有在64位系统上两种DMA内存域才有差别。在32位系统上本内存域是空的。
#endif
ZONE_NORMAL,//标记了可直接映射的内核段的普通内存域。这是在所有体系结构上保证都会存在的唯一内存域,但无法保证该地址范围对应了实际的物理内存。例如,如果AMD64系统有2G内存,那么所有内存都属于ZONE_DMA32范围,而ZONE_NORMAL则为空。
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,//标记了超出内核段的物理内存。
#endif
ZONE_MOVABLE,//它是一个虚拟内存域,在防止物理内存碎片的机制中需要使用该内存域,我会在后面的文章中讲解。
MAX_NR_ZONES//充当结束标记。在内核想要迭代系统中所有内存域时,会用到该变量。
};
各个内存域都关联了一个数组,用来阻止属于该内存域的物理内存页(在内核中称之为页帧)。对每个页帧,都分配了一个struct page实例以及所需的管理数据。各个内存结点都保存在一个单链表中,供内核遍历。处于性能考虑,在为进程分配内存时,内核总是试图在当前运行的CPU相关联的NUMA结点上进行。但这并不总是可行的,例如,该结点的内存可能已经用尽。对此情况,每个结点都提供了一个备用列表(借助于struct zonelist)。该列表包含了其他结点(和相关的内存域),可用于代替当前结点分配内存,列表项的位置越靠后,就越不适合分配。在UMA系统上,上图中只有一个pg_data_t结点,其他的都不变。
主要数据结构分析:
struct pg_data_t详细分析:
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];//是一个数组,包含了结点中各内存域的数据结构
struct zonelist node_zonelists[MAX_ZONELISTS];//指点了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存
int nr_zones;//保存结点中不同内存域的数目
#ifdef CONFIG_FLAT_NODE_MEM_MAP
struct page *node_mem_map;//指向page实例数组的指针,用于描述结点的所有物理内存页,它包含了结点中所有内存域的页。
#endif
struct bootmem_data *bdata;//在系统启动期间,内存管理子系统初始化之前,内核页需要使用内存(另外,还需要保留部分内存用于初始化内存管理子系统)。为解决这个问题,内核使用了前面文章讲解的自举内存分配器。bdata指向自举内存分配器数据结构的实例。
#ifdef CONFIG_MEMORY_HOTPLUG
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;//该NUMA结点第一个页帧的逻辑编号。系统中所有的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一)。
unsigned long node_present_pages; //结点中页帧的数目
unsigned long node_spanned_pages;//该结点以页帧为单位计算的长度,包含内存空洞。
int node_id;//全局结点ID,系统中的NUMA结点都从0开始编号
wait_queue_head_t kswapd_wait;//交换守护进程的等待队列,在将页帧换出结点时会用到。后面的文章会详细讨论。
struct task_struct *kswapd;//指向负责该结点的交换守护进程的task_struct。
int kswapd_max_order;//定义需要释放的区域的长度。
} pg_data_t;
struct zone详细分析:
struct zone {
/* Fields commonly accessed by the page allocator */
unsigned long pages_min, pages_low, pages_high;//如果空闲页多于pages_high,则内存域的状态时理想的;如果空闲页的数目低于pages_low,则内核开始将页换出到硬盘;如果空闲页低于pages_min,那么页回收工作的压力就比较大,因为内核中急需空闲页。
/*
* We don't know if the memory that we're going to allocate will be freeable
* or/and it will be released eventually, so to avoid totally wasting several
* GB of ram we must reserve some of the lower zone memory (otherwise we risk
* to run OOM on the lower zones despite there's tons of freeable ram
* on the higher zones). This array is recalculated at runtime if the
* sysctl_lowmem_reserve_ratio sysctl changes.
*/
unsigned long lowmem_reserve[MAX_NR_ZONES];//分别为各种内存域指定了若干页,用于一些无论如何都不能失败的关键性内存分配。
#ifdef CONFIG_NUMA
int node;
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
struct per_cpu_pageset *pageset[NR_CPUS];
#else
struct per_cpu_pageset pageset[NR_CPUS];//这个数组用于实现每个CPU的热/冷页帧列表。内核使用这些列表来保存可用于满足实现的“新鲜”页。但冷热页帧对应的高速缓存状态不同:有些页帧很可能在高速缓存中,因此可以快速访问,故称之为热的;未缓存的页帧与此相对,称之为冷的。
#endif
/*
* free areas of different sizes
*/
spinlock_t lock;
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#end
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
